Tutorial 2: Clasificación con scikit-learn¶
Miércoles 5 de septiembre de 2018
scikit-learn (o sklearn) es una librería que reúne muchas herramientas para realizar Minería de Datos y Aprendizaje de Máquinas. Permite hacer clasificación, clustering, entre otras. Además, incluye varios datasets para aprender a usar la librería.
En este tutorial vamos a reforzar los conceptos de aprendizaje supervisado y a mostrar cómo usar sklearn para entrenar nuestro primer clasificador.
Puedes ejecutar cada una de las celdas de código haciendo click en ellas y presionando Shift + Enter, o bien haciendo click en el ícono ⏭ que aparece al lado izquierdo de la celda.
También puedes editar cualquiera de estas celdas. Las celdas no son independientes. Es decir, sí importa el orden en el que las ejecutes, y cualquier cambio que hagas se reflejará en las celdas que ejecutes después.
Cargamos el Iris Dataset que viene en sklearn. El dataset incluye atributos de 3 especies de flores.
from sklearn.datasets import load_iris
iris = load_iris()
print("Atributos:", iris.feature_names)
print()
print("5 primeras filas:")
print(iris.data[0:5])
Los atributos del dataset son el largo y el ancho del pétalo y sépalo de cada flor.
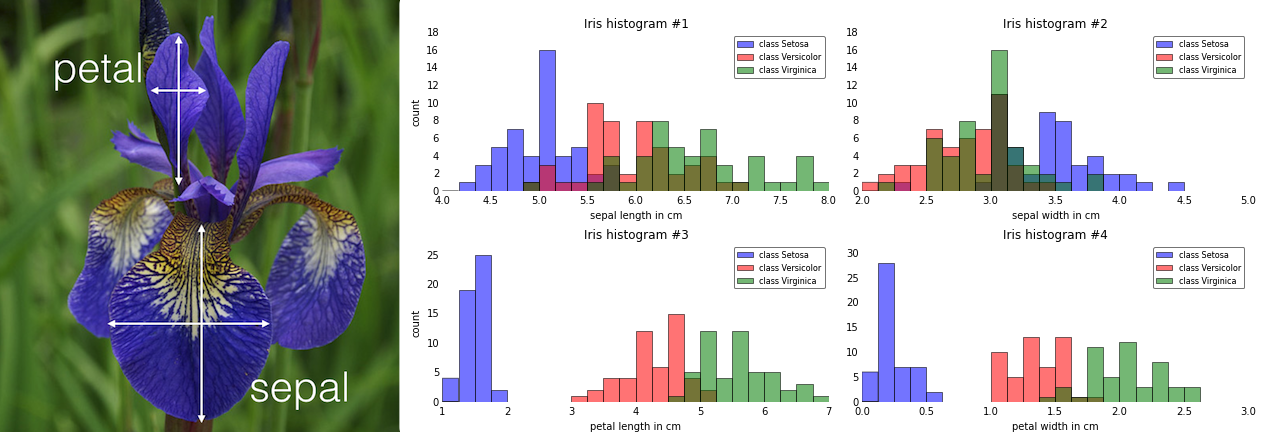
Las están dadas por el campo target, y los distintos tipos de target en el campo target_names:
print("target_names:", iris.target_names)
print()
print("Valores de la columna")
print(iris.target)
# vemos que hay 150 observaciones, 50 de cada una de las clases.
Vemos que los primeros valores de la columna target son ceros en vez del nombre de la especie. Lo que se usa comúnmente es mapear (asignar) números a variables categóricas. En este caso, el 0 corresponde a la primera especie en target_names, es decir, a iris setosa. El 1 corresponde a iris versicolor y el 2 a iris virginica.
Los datos que vienen en sklearn ya están listos para ser usados con los métodos de la librería. Si hubiésemos recibido los datos como una tabla, éstos se verían más o menos así:
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | target |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | iris-setosa |
| 4.9 | 3 | 1.4 | 0.2 | iris-setosa |
| ... | ... | ... | ... | ... |
| 5 | 2 | 3.5 | 1 | iris-versicolor |
| 5.9 | 3 | 5.1 | 1.8 | iris-virginica |
Una tarea que se nos podría plantear sería determinar, dados los atributos de una flor, cuál es la especie a la que corresponde. Por ejemplo, ¿a cuál especie corresponde la flor con los siguientes atributos?
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | target |
|---|---|---|---|---|
| 4.8 | 3 | 1.4 | 0.1 | ??? |
Nuestro primer clasificador¶
Vamos a usar un árbol de decisión como nuestro primer clasificador. Un árbol de decisión para este problema puede verse como el de la siguiente imagen:
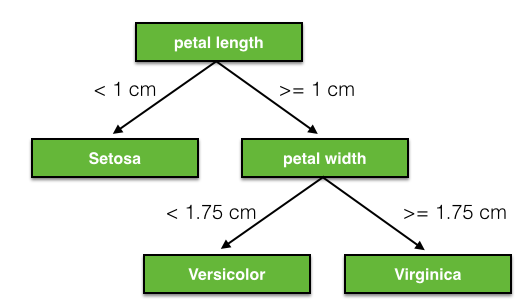
Nota que podemos mirar cualquiera de los atributos primero, o no usar algún otro atributo, por ejemplo:

En el último caso no usamos el petal width como atributo para el árbol. Y así, podemos tener muchos árboles distintos.
El proceso de entrenar un clasificador corresponde al proceso de —en este caso— encontrar las reglas del árbol que mejor se adapten a nuestros datos. Llamaremos al árbol resultante el modelo.
from sklearn.tree import DecisionTreeClassifier
# creamos un nuevo clasificador de árbol de decisión
clf = DecisionTreeClassifier()
# entrenamos el árbol, entregándole los datos de entrenamiento
clf.fit(iris.data, iris.target)
# el resultado de clf.fit() es el objeto DecisionTreeClassifier con los parámetros que usó para entrenar
Podemos visualizar el árbol generado usando graphviz
from sklearn import tree
import graphviz
gv = tree.export_graphviz(clf,
out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names)
graphviz.Source(gv)
¿Cómo evaluamos nuestro modelo?¶
¿Cómo sabemos qué tan bien le fue? Es decir, ¿logró aprender desde los datos cuáles eran las mejores reglas?
Una forma de ver esto es usando el modelo para clasificar nuevas instancias de los datos.
Sin embargo, no tenemos nuevas instancias, ya que entrenamos el clasificador con todos los datos disponibles. Si evaluamos nuestro clasificador con los datos de entrenamiento (es decir, los datos que usamos para entrenar el clasificador y generar un modelo), vamos a tener resultados sobre-optimistas, ya que el clasificador usó esos mismos datos para entrenar. Es como si fueras a dar una prueba y usaras la misma prueba con las respuestas para estudiar.
Esto también nos entrega una pista sobre qué significa que un clasificador aprenda de los datos. Para que un modelo se considere bueno, no basta con que clasifique correctamente los datos que usó para entrenar, sino que debe clasificar correctamente datos que no ha visto antes. Esto es a lo que se llama la capacidad de generalización del modelo.
Vamos a definir un par de conceptos antes de continuar:
El conjunto de datos de entrenamiento, o training set, es el conjunto de datos que le damos al clasificador para que pueda encontrar las reglas o parámetros óptimos que le permitan predecir la clase de estos datos.
El conjunto de datos de prueba, o test set, es el conjunto de datos sobre el cual vamos a evaluar el rendimiento de nuestro modelo. Estos datos se eligen antes de cualquier modificación o limpieza del dataset, y sólo se usan para evaluar el modelo entrenado.
(Una vez seguros de que nuestro modelo funciona bien y queremos usarlo "en producción", podemos entrenar con todos los datos disponibles. No antes)
El último punto es muy importante. Si por ejemplo, normalizamos los datos primero, y después separamos en training y test sets, estaremos "contaminando" nuestros datos de entrenamiento, dándoles información del test set y en cierta forma "haciendo trampa", afectando la capacidad de generalización del modelo resultante.
Holdout¶
Ahora vamos a tomar una muestra de los datos y separarlos en training set y test set, respectivamente. ¿Cómo determinamos esta muestra?
from sklearn.model_selection import train_test_split
X = iris.data
y = iris.target
# train_test_split separa X e y en dos conjuntos, train y test
# como hace un muestreo aleatorio, el resultado depende de algún proceso al azar
# el parámetro random_state fija la _semilla aleatoria_ de forma que el resultado siempre será el mismo
# esto es muy útil cuando uno quiere poder reproducir los resultados
# (el uso de 12 como la semilla es totalmente arbitrario)
# a todos ustedes les dará exactamente la misma partición de los datos
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=12)
Ahora podemos entrenar sólo con el training set:
clf = DecisionTreeClassifier(random_state=12)
clf.fit(X_train, y_train)
Para evaluar, predecimos usando una de las observaciones en el test set y contrastamos el resultado con la respuesta correcta:
x_ = X_test[0]
y_ = y_test[0]
# la clase es iris-versicolor
print("data:", x_)
print("clase:", y_)
# [x] es una lista que contiene como elemento a x
# predict recibe una lista de inputs y retorna un arreglo de enteros,
# cada entero es la clase que predice para cada elemento en la lista input
clf.predict([x_])
Vemos que acertó en este caso. En sklearn hay métodos que automatizan este proceso.
from sklearn.metrics import accuracy_score
y_pred = clf.predict(X_test)
print(accuracy_score(y_test, y_pred))
Vemos que el accuracy es de un 96%. Esto significa que clasificó correctamente el 96% de los datos en X_test.
Surgen dos preguntas a partir de esto:
- ¿Tuvimos suerte? Es decir, si hubiésemos elegido otra partición train/test, ¿obtendríamos resultados diferentes?
- ¿Qué pasa si las clases están desbalanceadas? ¿Cómo afecta al accuracy si tenemos, por ejemplo, 99% de una clase y 1% de otra?
Cross-Validation¶
¿Tuvimos suerte? Es decir, si hubiésemos elegido otra partición train/test, ¿obtendríamos resultados diferentes?
Cross-validation nos ayuda a disminuir el efecto del azar (pregunta 1). Por ejemplo, observa qué pasa si cambiamos la semilla aleatoria:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=37)
clf = DecisionTreeClassifier(random_state=12)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(accuracy_score(y_test, y_pred))
Para disminuir el efecto, cross-validation particiona los datos en $k$ partes iguales, entrena con $k-1$ partes, evalúa en la $k$-ésima, guarda el resultado, y vuelve a repetir el proceso con otras $k-1$ partes hasta haber recorrido todas las partes. Este proceso se llama $k$-fold cross-validation.
Observa que esto implica que el clasificador se entrenará $k$ veces, lo cual puede ser costoso dependiendo del clasificador y de la cantidad de datos.

from sklearn.model_selection import KFold
# 10-fold cv
kf = KFold(n_splits=10)
accuracies = []
for train_index, test_index in kf.split(X):
print("TRAIN:", train_index, "TEST:", test_index, sep='\n')
print()
X_train = X[train_index]
X_test = X[test_index]
y_train = y[train_index]
y_test = y[test_index]
clf = DecisionTreeClassifier(random_state=12)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
accuracies.append(accuracy)
print()
print(accuracies)
print(sum(accuracies) / len(accuracies))
Vemos que el promedio de los accuracies es $0.94$, más bajo que el $0.96$ y $0.98$ que obtuvimos antes.
Un caso extremo de cross-validation es cuando $k = N$, el número de filas en el dataset. Esto significa que vamos a entrenar $N$ veces el clasificador, y cada vez lo vamos a evaluar mirando un sólo dato a la vez. Esta forma de cross-validation se llama leave one out (LOO). LOO es útil cuando tenemos pocos datos para entrenar, por lo que dejar, por ejemplo, el 20% de los datos como testing puede ser considerable.
# 150-fold cv
kf = KFold(n_splits=150)
accuracies = []
for train_index, test_index in kf.split(X):
X_train = X[train_index]
X_test = X[test_index]
y_train = y[train_index]
y_test = y[test_index]
clf = DecisionTreeClassifier(random_state=12)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
accuracies.append(accuracy)
print(sum(accuracies) / len(accuracies))
Un problema con KFold es que siempre hace las particiones en los mismos lugares. Por ejemplo, observa qué pasa en este caso:
kf = KFold(n_splits=3)
accuracies = []
for train_index, test_index in kf.split(X):
X_train = X[train_index]
X_test = X[test_index]
y_train = y[train_index]
y_test = y[test_index]
clf = DecisionTreeClassifier(random_state=12)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
accuracies.append(accuracy)
print(sum(accuracies) / len(accuracies))
¿Por qué el accuracy es 0?
# ejemplo con shuffle=True
kf = KFold(n_splits=3, shuffle=True, random_state=12)
accuracies = []
for train_index, test_index in kf.split(X):
X_train = X[train_index]
X_test = X[test_index]
y_train = y[train_index]
y_test = y[test_index]
clf = DecisionTreeClassifier(random_state=12)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
accuracies.append(accuracy)
print(sum(accuracies) / len(accuracies))
Por otra parte, si las clases están desbalanceadas, es necesario hacer un muestreo estratificado (es decir, la distribución de clases de la muestra debe ser fiel a la distribución de clases original). Para eso podemos usar StratifiedKFold:
from sklearn.model_selection import StratifiedKFold
kf = StratifiedKFold(n_splits=3)
accuracies = []
# en este caso hay que entregarle tanto X como y a kf.split, ya que hará un split estratificado
for train_index, test_index in kf.split(X, y):
X_train = X[train_index]
X_test = X[test_index]
y_train = y[train_index]
y_test = y[test_index]
clf = DecisionTreeClassifier(random_state=12)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
accuracies.append(accuracy)
print(sum(accuracies) / len(accuracies))
Medidas de rendimiento de un clasificador¶
Volvamos a las preguntas que nos planteamos más arriba:
- ¿Tuvimos suerte? Es decir, si hubiésemos elegido otra partición train/test, ¿obtendríamos resultados diferentes?
- ¿Qué pasa si las clases están desbalanceadas? ¿Cómo afecta al accuracy si tenemos, por ejemplo, 99% de una clase y 1% de otra?
La (1) la respondimos disminuyendo el factor del azar evaluando varias veces con distintas muestras de los datos usando cross-validation.
Ahora, ¿qué pasa con el accuracy si tenemos clases desbalanceadas?
Clasificador dummy¶
Un clasificador dummy es un clasficador que no aprende nada de los datos, sino que sus reglas son siempre fijas.
Por ejemplo, imagina un modelo (para dos clases) que cada vez que viene una nueva observación, lanza una moneda, y dice clase A con un 50% de probabilidad, o clase B con un 50% de probabilidad. Si en los datos de prueba las clases A y B están balanceadas, el clasificador tendrá un 50% de accuracy, sin haber aprendido nada sobre los datos.
De esto se desprende la necesidad de un baseline. Es decir, sin hacer nada de esfuerzo, ¿cuál es el mínimo accuracy que puedo obtener? Piensa que si entrenara un clasificador muy sofisticado, y éste al final obtuviese un accuracy menor al baseline, entonces estamos haciendo algo muy mal. El baseline nos permite tener un punto de comparación (el baseline no tiene por qué ser algo muy simple tampoco).
from sklearn.dummy import DummyClassifier
kf = StratifiedKFold(n_splits=3)
accuracies = []
# vamos a repetir el proceso 100 veces
for i in range(100):
for train_index, test_index in kf.split(X, y):
X_train = X[train_index]
X_test = X[test_index]
y_train = y[train_index]
y_test = y[test_index]
# creamos el dummy classifier con estrategia al azar uniforme
clf = DummyClassifier(strategy="uniform")
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
accuracies.append(accuracy)
print(sum(accuracies) / len(accuracies))
Vemos que el accuracy promedio es de aproximadamente 33%, que es la proporción de elementos por cada clase.
Si las dos clases están desbalanceadas, supongamos en proporción 9:1, ¿qué tipo de clasificador dummy se te ocurre que puede tener un 90% de accuracy?
Matriz de confusión, Precision y Recall¶
La matriz de confusión nos permite observar los errores del clasificador:
from sklearn.metrics import confusion_matrix
random_seed = 54
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=random_seed)
clf = DecisionTreeClassifier(random_state=random_seed)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
confusion_matrix(y_test, y_pred)
La matriz se interpeta de la siguiente forma:
| iris-setosa | iris-versicolor | iris-virginica | ← clasificado como / clase real ↓ |
|---|---|---|---|
| 12 | 0 | 0 | iris-setosa |
| 0 | 17 | 1 | iris-versicolor |
| 0 | 2 | 18 | iris-virginica |
Por cada clase, podemos determinar el tipo de error que el modelo hace.
- Verdaderos Positivos (TP): el dato X es de la clase C, y el modelo clasifica X como C.
- Verdaderos Negativos (TN): el dato X no es de la clase C, y el modelo clasifica X como algo que no es C.
- Falsos Positivos (FP): el dato X no es de la clase C, pero el modelo clasifica a X como C.
- Falsos Negativos (FN): el dato X es de la clase C, pero el modelo clasifica a X como algo que no es C.
A partir de estas medidas, definimos dos medidas nuevas para una clase, precision y recall:
$$Precision = \frac{TP}{TP + FP}$$$$Recall = \frac{TP}{TP+FN}$$Nota que estas medidas son para una clase en particular. La medida para todo el dataset puede ser el promedio de la medida para cada clase.
Ver más en https://en.wikipedia.org/wiki/Precision_and_recall
from sklearn.metrics import classification_report
random_seed = 54
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=random_seed)
clf = DecisionTreeClassifier(random_state=random_seed)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
Cuando las clases están desbalanceadas, conviene mucho mirar el Precision y el Recall por cada clase.
Overfitting¶
Podemos decir que el overfitting es una incapacidad de generalización, usualmente debido a un sobreajuste (overfitting) a los datos con los que contamos.
Por ejemplo, en nuestro test set obtenemos un 94% de accuracy (y un alto precision y un alto recall). Sin embargo, cuando ponemos nuestro modelo "en producción", el accuracy disminuye radicalmente (ej. un 60%). Una posible causa de esto es que nuestro modelo se ajustó demasiado a los datos de entrenamiento.
El overfitting tiene muchas formas distintas. Mucho de lo que hemos visto en este tutorial apunta a tener buenas garantías de generalización en datos nunca vistos, dado que lo que queremos es poder generalizar a partir de una muestra (muy muy pequeña) a datos totalmente nuevos (de una cantidad arbitraria).
Algunas formas de evitar el overfitting:
- Evitar que nuestro modelo sea muy específico a los datos de entrenamiento (por ejemplo, evitando que el árbol de decisión tenga muchas ramas). Es decir, preferir modelos simples a modelos complejos.
- Usar cross-validation para tener una mejor garantía del rendimiento con datos nuevos (aunque esto no es posible si el entrenamiento toma mucho tiempo).
- No "contaminar" los datos de entrenamiento con los datos de prueba, o viceversa.
- Normalizar los datos o tratar de disminuir el ruido de éstos. Tener cuidado con los outliers.
- Tener más datos :-)
# ejemplo obtenido de http://scikit-learn.org/stable/auto_examples/model_selection/plot_underfitting_overfitting.html
import numpy as np
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score
np.random.seed(0)
def true_fun(X):
return np.cos(1.5 * np.pi * X)
n_samples = 30
degrees = [1, 4, 15]
X = np.sort(np.random.rand(n_samples))
y = true_fun(X) + np.random.randn(n_samples) * 0.1
plt.figure(figsize=(14, 5))
for i in range(len(degrees)):
ax = plt.subplot(1, len(degrees), i + 1)
plt.setp(ax, xticks=(), yticks=())
polynomial_features = PolynomialFeatures(degree=degrees[i],
include_bias=False)
linear_regression = LinearRegression()
pipeline = Pipeline([("polynomial_features", polynomial_features),
("linear_regression", linear_regression)])
pipeline.fit(X[:, np.newaxis], y)
# Evaluate the models using crossvalidation
scores = cross_val_score(pipeline, X[:, np.newaxis], y,
scoring="neg_mean_squared_error", cv=10)
X_test = np.linspace(0, 1, 100)
plt.plot(X_test, pipeline.predict(X_test[:, np.newaxis]), label="Model")
plt.plot(X_test, true_fun(X_test), label="True function")
plt.scatter(X, y, edgecolor='b', s=20, label="Samples")
plt.xlabel("x")
plt.ylabel("y")
plt.xlim((0, 1))
plt.ylim((-2, 2))
plt.legend(loc="best")
plt.title("Degree {}\nMSE = {:.2e}(+/- {:.2e})".format(
degrees[i], -scores.mean(), scores.std()))
plt.show()

En conclusión¶
El flujo usual a la hora de entrenar un clasificador es el siguiente:
- Tener datos. Verificar la fuente de los datos, la existencia de sesgos (sesgo de selección, sesgo del superviviente, sesgos sociodemográficos, etc.).
- Separar datos en train y test set.
- Realizar exploración y limpieza de datos en ambos sets, de manera independiente.
- Elegir clasificadores apropiados para el dominio del problema (próxima clase de cátedra)
- Determinar métricas de entrenamiento usando cross-validation, si es posible (más de esto en el lab de mañana).
- Evaluar en el test set.
- Usar todos los datos para entrenar el modelo que irá "a producción"
Referencias¶
- Documentación de scikit-learn. http://scikit-learn.org/stable/index.html
- Precision y Recall. https://en.wikipedia.org/wiki/Precision_and_recall
- Machine Learning 101 (Google). https://docs.google.com/presentation/d/1kSuQyW5DTnkVaZEjGYCkfOxvzCqGEFzWBy4e9Uedd9k/preview?imm_mid=0f9b7e&cmp=em-data-na-na-newsltr_20171213#slide=id.g168a3288f7_0_58
- WEKA (un programa visual con clasificadores y otras herramientas para ML). https://www.cs.waikato.ac.nz/ml/weka/
- Curso de Data Mining con WEKA. https://www.cs.waikato.ac.nz/ml/weka/mooc/dataminingwithweka/